|


游戏问答原文:DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
作者: Daochen Zha 1 Jingru Xie
代码: kwai/DouZero
一、简介二、斗地主的背景三、深度蒙特卡洛四、斗地主系统五、实验六、相关工作七、结论和未来工作一、简介
游戏是现实世界的抽象,人工agent在其中学习与其他agent竞争和合作。虽然在各种完全和不完全信息游戏中取得了重大成就,但斗地主(又称斗地主),一个三人纸牌游戏,仍然没有解决。斗地主是一个非常具有挑战性的领域,它有竞争、协作、不完全信息、大的状态空间,特别是有大量的可能行动,其中合法行动在不同的回合之间有很大的不同。不幸的是,现代强化学习算法主要集中在简单和小的行动空间,毫不奇怪,它们在斗地主中没有取得令人满意的进展。在这项工作中,我们提出了一个概念上简单而有效的斗地主人工智能系统,即DouZero,它用深度神经网络、动作编码和并行actor来增强传统的蒙特卡洛方法。DouZero在一台有四个GPU的服务器上从零开始,在几天的训练中就超过了所有现有的DouDizhu人工智能程序,并在Botzone排行榜上的344个人工智能agent中排名第一。通过构建DouZero,我们表明经典的蒙特卡洛方法可以在具有复杂行动空间的困难域中提供强大的结果。我们发布了代码和在线演示,希望这种洞察力能够激励未来的工作。
游戏经常作为人工智能的基准,因为它们是许多现实世界问题的抽象。在完美信息游戏中已经取得了重大的成就。例如,AlphaGo(Silver等人,2016)、AlphaZero(Silver等人,2018)和MuZero(Schrittwieser等人,2020)已经在围棋游戏中建立了最先进的性能。最近的研究已经发展到更具挑战性的不完全信息游戏,其中agent在一个部分可观察的环境中与他人竞争或合作。双人游戏已经取得了令人鼓舞的进展,例如简单的Leduc Holdem和限额/无限额的Texas Holdem(Zinkevich等人,2008;Heinrich Silver,2016;Moravcˇ´ık等人。2017;Brown Sandholm,2018),到多人游戏,如多人德州扑克(Brown Sandholm,2019b)、星际争霸(Vinyals等,2019)、DOTA(Berner等,2019)、Hanabi(Lerer等,2020)、麻将(Li等,2020a)、国王的荣誉(Ye等,2020b;a)和 No-Press Diplomacy(Gray等,2020)。
这项工作旨在为斗地主建立人工智能程序,斗地主是中国最流行的纸牌游戏,每天有数以亿计的活跃玩家。斗地主有两个有趣的特征,给人工智能系统带来了巨大的挑战。首先,斗地主中的玩家需要在一个部分可观察的环境中与他人竞争和合作,而且交流有限。具体来说,两个农民玩家将作为一个团队,与地主玩家进行对抗。扑克游戏的流行算法,如反事实后悔最小化(CFR)(Zinkevich等人,2008))及其变体,在这种复杂的三人游戏环境中往往不健全。其次,斗地主有大量的信息集,其平均规模非常大,并且由于牌的组合,有一个非常复杂和庞大的行动空间,多达104种可能的行动(Zha等人,2019a)。与德州扑克不同,斗地主中的行动不容易被抽象化,这使得搜索的计算成本很高,常用的强化学习算法也不太有效。深度Q-Learning(DQN)(Mnih等人,2015)在非常大的动作空间中由于高估问题而存在问题(Zahavy等人,2018);策略梯度方法,如A3C(Mnih等人,2016),不能利用斗地主中的动作特征,因此不能像DQN(Dulac-Arnold等人,2015)那样自然地对未见过的动作进行泛化。毫不奇怪,以前的工作表明,DQN和A3C不能在斗地主中取得令人满意的进展。在(You等人,2019)中,DQN和A3C被证明在面对简单的基于规则的agent时,即使有二十天的训练,也只有不到20%的胜率;(Zha等人,2019a)中的DQN只比均匀采样合法动作的随机agent稍好。
之前有一些人通过将人类启发式方法与学习和搜索相结合来构建斗地主AI。组合Q网络(CQN)(You等人,2019)提出通过将行动解耦为分解选择和最终行动选择来减少行动空间。然而,分解依赖于人类的启发式方法,而且速度极慢。在实践中,CQN在二十天的训练后甚至不能击败简单的启发式规则。DeltaDou(Jiang等人,2019)是第一个与顶级人类棋手相比达到人类水平的人工智能程序。它通过使用贝叶斯方法来推理隐藏信息,并根据自己的策略网络对其他玩家的行动进行采样,从而实现类似AlphaZero的算法。为了抽象出行动空间,DeltaDou根据启发式规则预训练了一个踢球者网络。然而,踢球者在DouDizhu中扮演着重要的角色,不容易被抽象化。踢球者选择不当可能会直接导致输掉比赛,因为它可能会破坏一些其他的牌类,例如,独行链。此外,贝叶斯推理和搜索的计算成本很高。即使在用监督回归启发式方法初始化网络时,也需要两个多月的时间来训练DeltaDou(Jiang等人,2019)。因此,现有的DouDizhu人工智能程序的计算成本很高,而且可能是次优的,因为它们高度依赖与人类知识的抽象。
在这项工作中,我们提出了DouZero,这是一个概念上简单但有效的斗地主人工智能系统,没有抽象的状态/行动空间或任何人类知识。DouZero用深度神经网络、行动编码和平行actor加强了传统的蒙特卡洛方法(Sutton Barto, 2018)。DouZero有两个理想的特性。首先,与DQN不同,它不容易受到高估偏差的影响。其次,通过将行动编码为卡片矩阵,它可以自然地概括整个训练过程中不经常出现的行动。这两个特性对于处理斗地主庞大而复杂的动作空间至关重要。与许多树形搜索算法不同,斗地主是基于抽样的,这使得我们可以使用复杂的神经架构,在相同的计算资源下,每秒产生更多的数据。与之前许多依赖特定领域抽象的扑克牌人工智能研究不同,DouZero不需要任何领域知识或基础动态知识。在只有48个核和4个1080Ti GPU的单一服务器中从头开始训练,DouZero在半天内就超过了CQN和启发式规则,在两天内击败了我们的内部监督agent,并在10天内超过了DeltaDou。广泛的评估表明,DouZero是迄今为止最强大的DouDizhu AI系统。
通过构建DouZero系统,我们证明了经典的蒙特卡洛方法可以在大规模和复杂的纸牌游戏中取得强大的结果,这些游戏需要在巨大的状态和行动空间中推理竞争和合作。我们注意到,一些工作也发现蒙特卡洛方法可以实现竞争性能(Mania等人,2018;Zha等人,2021a),并在稀疏的奖励设置中有所帮助(Guo等人,2018;Zha等人,2021b)。与这些专注于简单和小环境的研究不同,我们展示了蒙特卡洛方法在大规模纸牌游戏上的强大性能。我们希望这一见解能够促进未来关于解决多agent学习、稀疏奖励、复杂行动空间和不完美信息的研究,我们已经发布了我们的环境和训练代码。与许多扑克牌人工智能系统在训练中需要成千上万的CPU不同,例如DeepStack(Moravcˇ´ık等人,2017)和Libratus(Brown Sandholm,2018),DouZero实现了一个合理的实验pipeline,只需要在一个GPU服务器上进行几天的训练,这对大多数研究实验室来说是可以承受的。我们希望它能激励这一领域的未来研究,并作为一个强大的基线。
二、斗地主的背景
斗地主是一种流行的三人纸牌游戏,容易学习但难以掌握。它在中国吸引了数以亿计的玩家,每年都有许多锦标赛举行。它是一种舍牌型游戏,玩家的目标是在其他玩家之前清空自己手中的所有牌。两个农民玩家作为一个团队,与另一个地主玩家进行对抗。如果其中一个农民玩家率先没有牌,则农民获胜。每个游戏都有一个竞标阶段,玩家根据手牌的强度竞标地主,还有一个打牌阶段,玩家轮流打牌。我们在附录A中提供了详细的介绍。
DouDizhu仍然是一个未解决的多agent强化学习的基准(Zha等人,2019a;Terry等人,2020)。有两个有趣的特性使得斗地主的解决特别具有挑战性。首先,农民需要合作对抗地主。例如,图10显示了一个典型的情况,底层的农民可以选择下一个Solo,以帮助右侧的农民获胜。第二,由于牌的组合,斗地主有一个复杂而庞大的行动空间。有27472种可能的组合,其中这些组合的不同子集将在不同的手牌中是合法的。图1显示了一个手牌的例子,它有391种合法的组合,包括Solo、对子、三人、炸弹、飞机、四人等。行动空间不容易被抽象化,因为不适当的出牌可能会打破其他类别,直接导致输掉一局。因此,建立斗地主人工智能是具有挑战性的,因为斗地主中的玩家需要在巨大的行动空间中对竞争和合作进行推理。

图1: 手牌和可能合法的动作组合
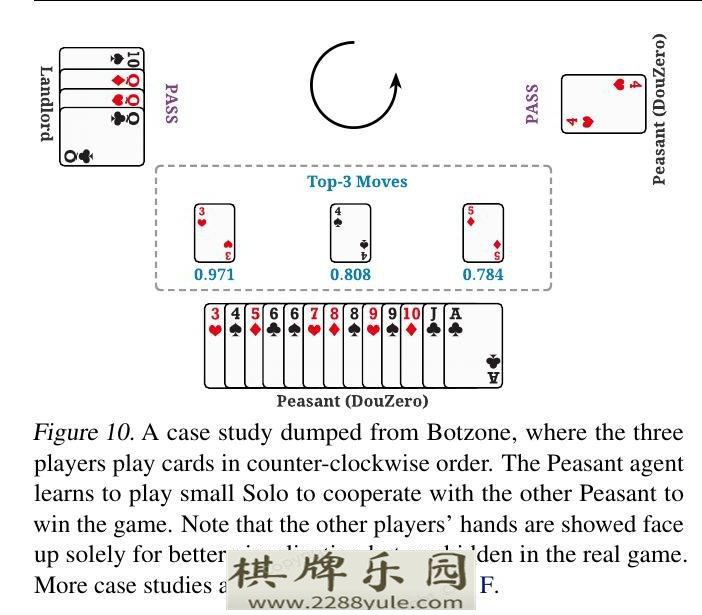
图10: 一个从Botzone甩出来的案例,三个玩家按逆时针顺序出牌。农民agent学会了打solo,与其他农民合作以赢得游戏。请注意,其他玩家的手牌朝上显示完全是为了更好的可视化,但在真实游戏中是隐藏的。更多案例研究见附录F。三、深度蒙特卡洛
在这一节中,我们重新审视蒙特卡洛(MC)方法,并介绍了深度蒙特卡洛(DMC),它用深度神经网络概括了MC,用于函数逼近。然后,我们讨论并比较了DMC与策略梯度方法(如A3C)和DQN,后者在DouDizhu中被证明是失败的(You等人,2019;Zha等人,2019a)。
3.1. 深度神经网络的蒙特卡洛方法
蒙特卡洛(Monte-Carlo,MC)方法是传统的强化学习算法,基于样本回报的平均化(Sutton Barto,2018)。MC方法是为偶发任务设计的,其中经验可分为偶发episode,所有偶发episode最终都会终止。为了优化策略π,每次访问MC可以通过迭代执行以下程序来估计Q-table,Q(s,a)。
使用π生成一个episode。2. 对于每个s,a出现的episode,计算并更新Q(s, a)与所有关于s,a的样本的平均回报。
3. 对于episode中的每个s, 
第2步的平均回报通常是由折扣的累积奖励得到的。与依靠引导的Q-learning不同,MC方法直接近似于目标Q值。在步骤1中,我们可以使用epsilon-greedy来平衡探索和开发。上述程序可以自然地与深度神经网络相结合,这就导致了深度蒙特卡洛(DMC)。具体来说,我们可以用神经网络取代Q-table,并在步骤2中使用均方误差(MSE)来更新Q网络。
虽然MC方法被判断为不能处理不完整的episode,并且由于高方差而被认为是低效的(Sutton Barto, 2018),但DMC非常适用于DouDizhu。首先,DouDizhu是一个episode性的任务,因此我们不需要处理不完整的episode。其次,DMC可以很容易地并行化,以便每秒有效地生成许多样本,缓解高方差问题。
3.2. 与策略梯度方法的比较
策略梯度方法,如REINFORCE(Williams,1992)、A3C(Mnih等人,2016)、PPO(Schulman等人,2017)和IMBALA(Espeholt等人,2018),在强化学习中非常流行。他们以建模为目标,直接用梯度下降法优化策略。在策略梯度方法中,我们通常使用一个类似分类器的函数近似器,其输出与行动的数量呈线性比例。虽然策略梯度方法在大的行动空间中工作良好,但它们不能使用行动特征来推理以前未见过的行动(Dulac-Arnold等人,2015)。在实践中,斗地主中的行动可以自然地编码为卡片矩阵,这对推理至关重要。例如,如果agent因为选择了一个漂亮的踢球者而得到了行动3KKK的奖励,它也可以将这一知识概括为未来未见的行动,例如3JJJ。这一特征对于处理非常大的动作空间和加速学习至关重要,因为许多动作在模拟数据中并不经常出现。
DMC可以很自然地利用动作特征来概括未见过的动作,把动作特征作为输入。虽然如果动作规模很大,它的执行复杂度可能会很高,但在斗地主的大多数状态下,只有一个动作子集是合法的,所以我们不需要对所有的动作进行迭代。因此,DMC对于斗地主来说总体上是一种高效的算法。虽然有可能将动作特征引入到actor-critic框架中(例如,通过使用Q网络作为critic),但类似分类器的actor仍然会受到大动作空间的影响。我们的初步实验证实,这种策略不是很有效(见图7)。
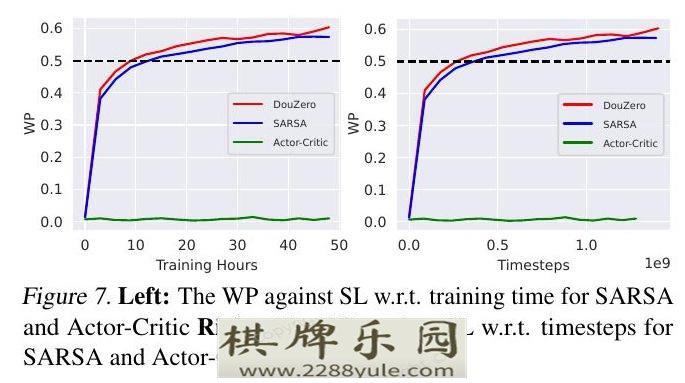
图7: 左图:SARSA和Actor-Critic的WP对SL的训练时间右图。SARSA和Actor-Critic的WP对SL的时间步数的影响。
3.3. 与深度Q-learning的比较
最流行的基于价值的算法是深度QLearning(DQN)(Mnih等人,2015),它是一种自举方法,根据下一步的Q值来更新Q值。虽然DMC和DQN都近似于Q值,但DMC在斗地主中具有几个优势。
首先,在DQN中近似最大行动值所引起的高估偏差在使用函数近似时很难控制(Thrun Schwartz, 1993 Hasselt, 2010),并且在行动空间非常大的情况下变得更加明显(Zahavy等人,2018)。虽然一些技术,如double Q-learning(van Hasselt等人,2016)和经验重放(Lin,1992),可能会缓解这个问题,但我们在实践中发现,DQN非常不稳定,经常在DouDizhu发散。而Monte-Carlo估计不容易出现偏差,因为它直接接近真实值,不需要自举(Sutton Barto, 2018)。
第二,斗地主是一个具有长视野和稀疏奖励的任务,也就是说,agent需要经历一长串没有反馈的状态,而且唯一产生非零奖励的时间是在游戏结束时。这可能会减慢Q-learning的收敛速度,因为估计当前状态下的Q值需要等到下一个状态下的值接近其真实值(Szepesva´ri, 2009 Beleznay等人,1999)。与DQN不同,Monte-Carlo估计的收敛性不受episode长度的影响,因为它直接接近真实的目标值。
第三,由于行动空间大且多变,在DouDizhu中有效实现DQN是不方便的。具体来说,DQN在每个更新步中的最大运算将导致高计算开销,因为它需要在一个非常昂贵的深Q网络上迭代所有合法动作。此外,合法动作在不同的状态下是不同的,这使得它不方便进行批次学习。因此,我们发现DQN在壁钟时间方面太慢了。虽然MonteCarlo方法可能会受到高方差的影响(Sutton Barto, 2018),这意味着它可能需要更多的样本来收敛,但它可以很容易地并行化,每秒产生成千上万的样本,以缓解高方差问题并加速训练。我们发现,DMC的高方差被它提供的可扩展性大大抵消了,DMC在壁钟时间内非常高效。
四、斗地主系统
在这一节中,我们首先介绍了DouZero系统,描述了状态/动作表示和神经结构,然后阐述了我们如何用多进程并行化DMC,以稳定和加速训练。
4.1. 牌的表示和神经结构
我们用一个4×15的one-hot矩阵对每个牌的组合进行编码(图2)。由于花色在斗地主中无关紧要,我们用每一行来代表特定等级或小丑的牌数。图3显示了Q网络的结构。对于状态,我们提取几个牌矩阵来代表手牌,其他玩家的手牌和最近的动作的结合,以及一些one-hot向量来表示其他玩家的牌数和到目前为止的炸弹数量。同样地,我们使用一个卡片矩阵来编码行动。对于神经结构,LSTM被用来编码历史动作,输出与其他状态/动作特征相拼接。最后,我们使用六层的MLP,隐藏层大小为512,以产生Q值。我们在附录C.1中提供更多细节。
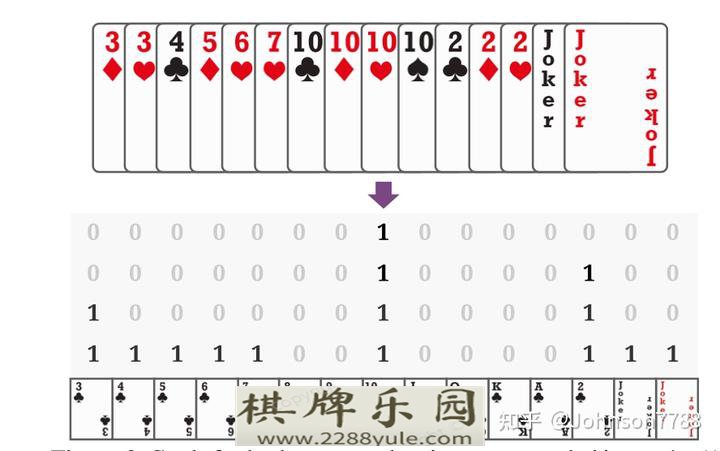
图2: 状态和行动的牌都被编码为4×15的one-hot矩阵,其中列对应于13个牌和小丑,每一行对应于特定牌或小丑的牌的数量。更多的例子在附录B中提供。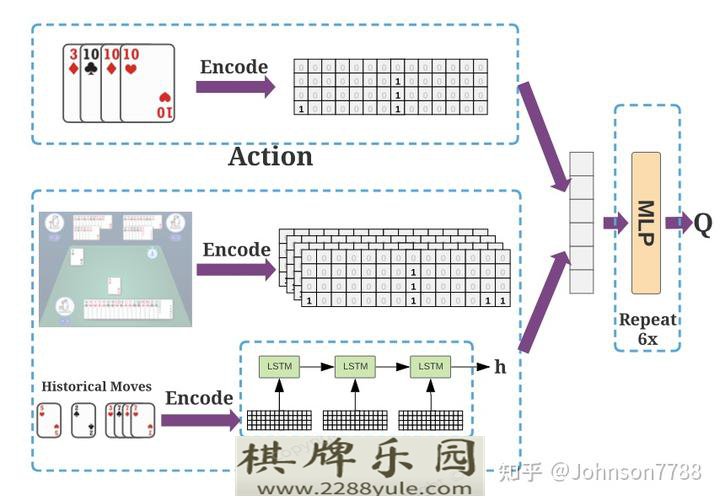
图3. DouZero的Q网络由一个编码历史动作的LSTM和6层隐藏维度为512的MLP组成。该网络根据行动和状态的拼接表示,预测给定状态-行动对的数值。更多细节见附录C.1。4.2. 平行的actor
我们用L表示地主,用U表示在地主之前移动的玩家,用D表示在地主之后移动的玩家。我们用多个actor进程和一个学习者进程来并行化DMC,分别总结为算法1和算法2。学习者为三个位置维护三个全局Q网络,并根据actor进程提供的数据,用MSE损失更新网络,以接近目标值。每个actor维护三个本地Q网络,这些网络定期与全局网络同步。actor将从游戏引擎中重复采样轨迹,并计算每个状态-动作对的累积奖励。学习者和actor的通信是通过三个共享缓冲区实现的。每个缓冲区都被分成几个条目,每个条目由几个数据实例组成。

算法1 DouZero的actor过程
算法2 DouZero的学习者过程五、实验
实验的目的是回答以下研究问题。RQ1:DouZero与现有的DouDizhu方案,如基于规则的策略、监督学习、基于RL的方法和基于MCTS的方案相比如何(第5.2节)?RQ2:如果我们考虑竞价阶段,DouZero的表现如何(第5.3节)?RQ3:DouZero的训练效率如何(第5.4节)?RQ4:DouZero与bootstrapping和actor critic方法相比如何(第5.5节)?RQ5:DouZero学习到的出牌策略是否与人类知识一致(第5.6节)?RQ6:与现有程序相比,DouZero在推理中的计算效率高吗(第5.7节)?RQ7:DouZero的两个农民能否学会相互合作(第5.8节)?
5.1. 实验设置
扑克游戏中常用的策略强度衡量标准是可利用性(Johanson等人,2011)。然而,在斗地主中,计算可利用性本身是难以实现的,因为斗地主有巨大的状态/行动空间,而且有三个玩家。为了评估性能,按照(Jiang等人,2019),我们发起了包括地主和农民两个对手方的锦标赛。我们通过对每副牌进行两次比赛来减少变异。具体来说,对于两个竞争的算法A和B来说,他们将首先分别作为地主和农民的位置,对给定的卡组进行比赛。然后,他们交换立场,即A采取农民立场,而B采取地主立场,并再次玩同一副牌。为了模拟真实环境,在第5.3节中,我们进一步用监督学习训练一个竞争网络,agent将根据手牌的强度在每一局中竞争地主(更多细节见附录C.2)。我们考虑以下竞争性算法。
- DeltaDou。一个强大的人工智能程序,它使用贝叶斯方法来推理隐藏信息,并用MCTS搜索行动数(Jiang等人,2019)。我们使用作者提供的代码和预训练的模型。该模型经过两个月的训练,显示出与顶级人类玩家同等的性能。
- CQN: Combinational Q-Learning(You等人,2019)是一个基于牌的分解和深度Q-Learning的程序。我们使用作者提供的开源代码和预训练的模型。
- SL:有监督的学习基线。我们在内部收集了226,230场人类专家比赛,这些比赛来自于我们的斗地主游戏手机应用中的最高级别的玩家。然后,我们使用与DouZero相同的状态表示和神经结构,用这些数据产生的49,990,075个样本来训练有监督的agent。更多细节见附录C.2。
- 基于规则的程序。我们收集了一些开源的基于启发式的程序,包括RHCP4,一个名为RHCP-v25的改进版本,以及RLCard包6(Zha等人,2019a)中的规则模型。此外,我们还考虑了一个随机程序,该程序对合法的动作进行统一采样。
衡量标准。按照(Jiang等人,2019),给定一个算法A和一个对手B,我们用两个指标来比较A和B的性能。
- WP(胜率)。甲方所赢的比赛数量除以总的比赛数量。
- ADP(平均分差)。A和B之间每场比赛的平均分差。基点是1,每颗炸弹会使分数翻倍。
我们在实践中发现,这两个指标鼓励不同风格的策略。例如,如果使用ADP作为奖励,agent倾向于非常谨慎地玩炸弹,因为玩炸弹有风险,可能会导致更大的ADP损失。相反,以WP为目标,agent倾向于积极地玩炸弹,即使会输,因为炸弹不会影响WP。我们观察到,用ADP训练的agent在ADP方面的表现略好于用WP训练的agent,反之亦然。在下文中,我们分别以ADP和WP为目标训练并报告两个DouZeroagent的结果。关于这两个目标的更多讨论在附录D.2中提供。
我们首先通过让每对算法玩10,000副牌来发起一个初步的锦标赛。然后,我们通过玩100,000副牌,计算出前三名算法的Elo评分,以进行更可靠的比较,即DouZero、DeltaDou和SL。如果一个算法在这副牌上进行的两场比赛中取得了更高的WP或ADP之和,那么这个算法就赢得了这副牌。我们用不同的随机抽样的牌组重复这个过程五次,并报告Elo分数的平均值和标准偏差。对于竞价阶段的评估,每副牌在不同位置的DouZero、DeltaDou和SL的不同扰动下进行六次。我们报告的是100,000副牌的结果。
实施细节。我们在一台有48个英特尔(R)至强(R)4214R CPU @ 2.40GHz的处理器和四个1080 Ti GPU的服务器上运行所有实验。我们使用45个actor,它们被分配到三个GPU上。我们在其余的GPU上运行一个学习器来训练Q网络。我们的实现是基于TorchBeast框架(Ku¨ttler等人,2019)。详细的训练曲线在附录D.5中提供。每个共享缓冲区有B=50个条目,大小为S=100,批次大小M=32,ε=0.01。我们设置了折扣系数γ=1,因为斗地主只在最后一个时间段有非零的奖励,早期的动作是非常重要的。我们使用ReLU作为MLP各层的激活函数。我们采用RMSprop优化器,学习率ψ=0.0001,平滑常数0.99,ε=10-5。我们对DouZero进行了30天的训练。
5.2. 对照现有计划的表现
为了回答RQ1,我们将DouZero与基线进行了离线比较,并在Botzone(Zhou等人,2018)这个斗地主比赛的在线平台上报告其结果(更多细节见附录E)。
表1总结了DouZero和所有基线之间头对头完成的WP和ADP。我们有三个看法。首先,DouZero在所有基于规则的策略和监督学习中占优势,这证明了在DouDizhu中采用强化学习的有效性。第二,DouZero的性能明显优于CQN。回顾一下,CQN类似于用动作分解和DQN来训练Q网络。DouZero的优势表明,DMC确实是训练斗地主的有效方法。第三,DouZero优于文献中最强的DouDizhu AI DeltaDou。我们注意到,斗地主具有非常高的变异性,也就是说,要赢得游戏依赖于初始手牌的强度,这高度依赖于运气。因此,0.586的WP和0.258的ADP表明比DeltaDou有明显的改善。此外,DeltaDou在训练和测试时都需要搜索。而DouZero不做搜索,这验证了DouZero学到的Q网络是非常强大的。
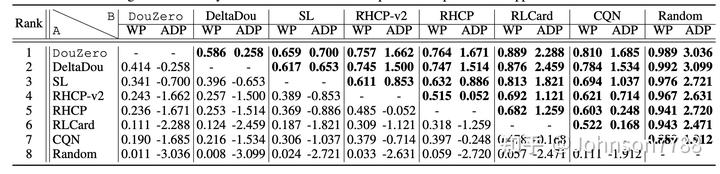
表1: 通过播放10,000张随机抽样的牌,DouZero与现有的DouDizhu程序的性能。如果WP大于0.5或ADP大于0,则算法A优于B(用黑体字突出)。算法的排名是根据它们击败的其他算法的数量来决定的。每个位置的完整结果都在附录D.1中提供。图4的左侧显示了DouZero、DeltaDou和SL通过玩100,000副牌的Elo评级得分。我们观察到,DouZero在WP和ADP方面都明显优于DeltaDou和SL。这再次证明了DouZero的强大性能。
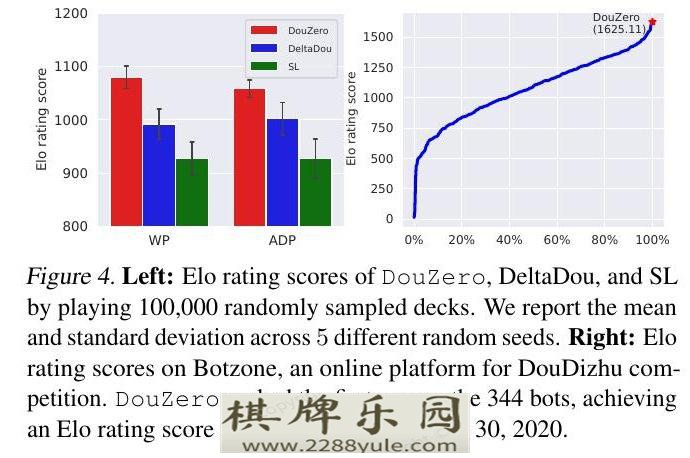
图4. 左图:DouZero、DeltaDou和SL通过玩100,000个随机抽样的牌组获得的Elo评级分数。我们报告了5个不同随机种子的平均值和标准偏差。右边。在Botzone,一个用于斗地主比赛的在线平台上的Elo评分。DouZero在344个机器人中排名第一,截至2020年10月30日,取得了1625.11的Elo评级分数。图4的右侧显示了DouZero在Botzone排行榜上的表现。我们注意到,Botzone采用了不同的得分机制。除了WP之外,它还对一些特定的牌类给予额外的奖励,如Chain of Pair和Rocket(详见附录E)。虽然如果使用Botzone的评分机制作为目标,DouZero很可能取得更好的表现,但我们直接上传了以WP为目标训练的DouZero预训练模型。我们观察到,这个模型足够强大,可以击败其他机器人。
5.3. 与投标阶段的比较
为了研究RQ2,我们使用人类专家数据训练了一个有监督学习的网络。我们将前三名算法,即DouZero、DeltaDou和SL,放入斗地主游戏的三个席位。在每个游戏中,我们随机选择第一个投标人,并用预训练好的投标网络来模拟投标阶段。为了公平比较,三种算法都使用了相同的投标网络。结果总结在表2中。尽管DouZero是在没有投标网络的情况下随机生成的牌组上训练的,但我们观察到DouZero在WP和ADP方面都比其他两种算法占优势。这证明了DouZero在需要考虑投标阶段的真实世界比赛中的适用性。

表2: 通过播放100,000张随机抽样的牌,对DouZero、DeltaDou和SL与投标阶段进行比较。5.4. 学习进度分析
为了研究RQ3,我们在图5中直观地展示了DouZero的学习进度。我们用SL和DeltaDou作为对手,画出WP和ADP训练天数变化的曲线。我们提出以下两点意见。首先,DouZero在一天和两天的训练中,在WP和ADP方面分别优于SL。我们注意到,DouZero和SL使用完全相同的神经结构进行训练。因此,我们把DouZero的优越性归功于自我对战的强化学习。虽然SL也表现良好,但它依赖于大量的数据,这并不灵活,可能会限制其性能。其次,DouZero在三天和十天的训练中,在WP和ADP方面分别优于DeltaDou。我们注意到,DeltaDou是通过对启发式的监督学习来初始化的,并且训练了两个多月。而DouZero从零开始,只需要几天的训练就能打败DeltaDou。这表明在DouDizhu中,没有搜索的model-free强化学习确实是有效的。
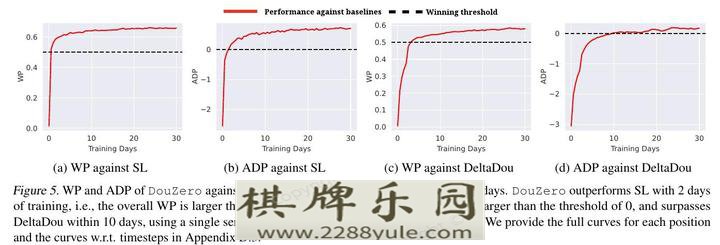
图5: DouZero的WP和ADP与SL和DeltaDou在训练天数上的对比。DouZero在2天的训练中就超过了SL,即整体WP大于0.5的阈值,整体ADP大于0的阈值,并在10天内超过了DeltaDou,使用一台有4个1080 Ti GPU和48个处理器的服务器。我们在附录D.3中提供了每个位置的完整曲线和相对于时间步长的曲线。
我们进一步分析了使用不同数量的actor时的学习率。图6报告了使用15、30和45个actor时的性能与SL的对比。我们观察到,使用更多的actor可以加速训练的壁时钟时间。我们还发现,这三种设置都显示出类似的采样效率。在未来,我们将探索在多个服务器上使用更多actor的可能性,以进一步提高训练效率。
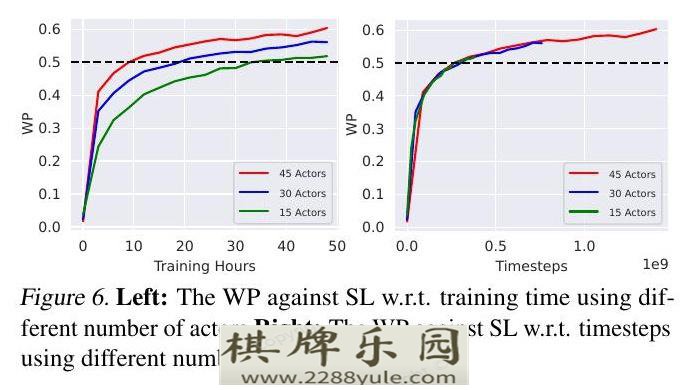
图6. 左图:使用不同数量的actor,在训练时间内对SL的WP右图。使用不同数量的actor,针对SL的WP在时间上的变化。5.5. 与SARSA和actor-critic家的比较
为了回答RQ4,我们在DouZero基础上实现了两个变体。首先,我们用时差(TD)目标取代DMC目标。这导致了SARSA的一个深度版本。第二,我们实现了一个具有行动特征的actor-critic变体。具体来说,我们使用Q网络作为具有行动特征的critic,并将策略训练为具有行动mask的actor,以消除非法行动。
图7显示了SARSA和Actor-Critic的单次运行结果。首先,我们没有观察到使用TD学习的明显好处。我们观察到DMC在壁钟时间和采样效率上比SARSA学习的速度略快。可能的原因是TD学习在稀疏奖励设置中不会有太大帮助。我们认为需要更多的研究来了解TD学习何时会有帮助。第二,我们观察到 "actor-critic "失败了。这表明,简单地将动作特征添加到critic身上可能不足以解决复杂的动作空间问题。在未来,我们将研究是否能有效地将动作特征纳入actor-critic框架中。
5.6. 对专家数据的DouZero分析
对于RQ5,我们计算了DouZero在整个训练过程中对人类数据的准确性。我们把用ADP训练的模型作为目标报告,因为收集人类数据的游戏应用也采用了ADP。图8显示了结果。我们做了以下两个有趣的观察。首先,在早期阶段,即训练的前五天,准确性不断提高。这表明,agent可能已经学会了一些与人类专业知识相一致的纯粹的自我对战的策略。其次,在训练的五天后,准确率急剧下降。我们注意到,五天后针对SL的ADP仍在提高。这表明agent可能已经发现了一些人类不容易发现的新颖而强大的策略,这再次验证了自我游戏强化学习的有效性。
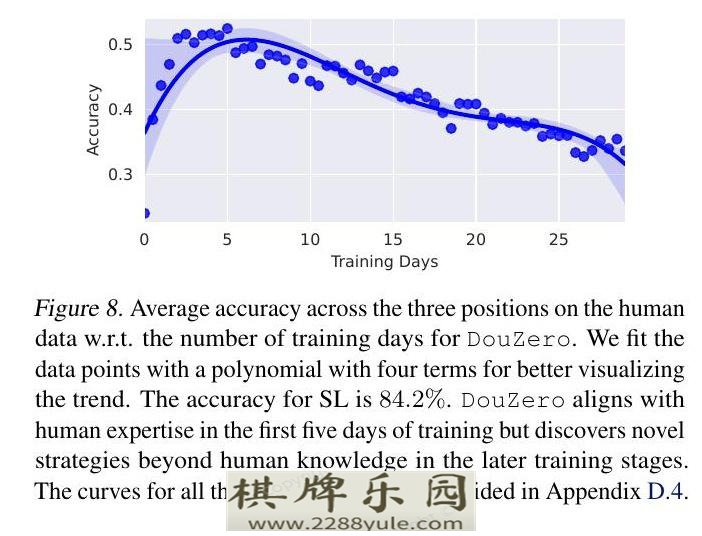
图8: 在人类数据上,三个位置的平均准确率与DouZero的训练天数有关。我们用四项的多项式来拟合数据点,以更好地显示趋势。SL的精确度为84.2%。DouZero在训练的前五天与人类的专业知识相一致,但在后面的训练阶段发现了超出人类知识的新策略。所有三个位置的曲线都在附录D.4中提供。5.7. 推理时间的比较
为了回答RQ6,我们在图9中报告了每一步的平均推理时间。为了进行公平的比较,我们在CPU上评估所有的算法。我们观察到,DouZero比DeltaDou、CQN、RHCP和RHCP-v2快几个数量级。这是意料之中的,因为DeltaDou需要进行大量的蒙特卡洛模拟,而CQN、RHCP和RHCP-v2需要昂贵的卡片分解。而DouZero在每步中只执行一次神经网络的前向传递。DouZero的高效推理使我们能够每秒产生大量的样本用于强化学习。这也使得在现实世界的应用中部署模型的费用可以承受。
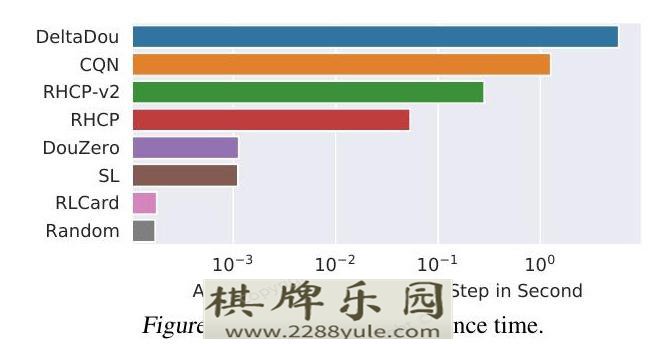
图9: 推理时间的比较。5.8. 案例研究
为了研究RQ7,我们进行了案例研究,以了解DouZero的决策。我们从Botzone转储比赛的日志,并将顶级行动与它们的预测Q值可视化。我们在附录F中提供了大部分的案例研究,包括好的和坏的案例。
图10显示了两个农民可以合作击败地主的典型情况。右手边的农民只剩下一张牌。在这里,底层的农民可以下一个solo,帮助另一个农民获胜。当研究DouZero预测的前三个行动时,我们有两个有趣的观察。首先,我们发现所有由DouZero输出的顶级行动都是solo,有很高的获胜信心,这表明DouZero的两个农民可能已经学会了合作。第二,行动4的预测Q值(0.808)远远低于行动3(0.971)。一个可能的解释是,外面还有一个4,因此,下4不一定能帮助农民获胜。实际上,在这个具体案例中,另一个农民的唯一牌的等级不高于4。总的来说,在这种情况下,行动3确实是最好的一步。
六、相关工作
搜索不完美信息的游戏。反事实后悔最小化(CFR)(Zinkevich等人,2008)是扑克游戏的领先迭代算法,有许多变体(Lanctot等人,2009;Gibson等人,2012;Bowling等人,2015;Moravcˇ´ık等人,2017;Brown Sandholm,2018;2019a;Brown等人,2019;Lanctot等人,2019;Li等人,2020b)。然而,遍历斗地主的游戏树是计算密集型的,因为它有一个巨大的树,有一个大的分支因子。此外,大多数先前的研究集中在零和设置上。虽然有些人致力于解决合作环境,例如蓝图策略(Lerer等人,2020),但对竞争和合作的推理仍然具有挑战性。因此,斗地主还没有看到一个有效的类似CFR的解决方案。
不完美信息游戏的RL。最近的研究表明,强化学习(RL)可以在扑克游戏中取得有竞争力的表现(Heinrich等人,2015;Heinrich Silver,2016;Lanctot等人,2017)。与CFR不同,RL是基于抽样的,所以它可以很容易地泛化到大规模的游戏。RL已经成功地应用于一些复杂的不完美信息游戏,如《星际争霸》(Vinyals等人,2019)、《DOTA》(Berner等人,2019)和《麻将》(Li等人,2020a)。最近,RL+搜索被探索并显示在扑克游戏中是有效的(Brown等人,2020)。DeltaDou采用了类似的想法,它首先推理出隐藏的信息,然后使用MCTS将RL与搜索结合在一起,在DouDizhu(Jiang等人,2019)。然而,DeltaDou的计算成本很高,而且严重依赖人类的专业知识。在实践中,即使没有搜索,我们的DouZero在几天的训练中也优于DeltaDou。
七、结论和未来工作
这项工作为斗地主提出了一个强大的人工智能系统。一些独特的属性使得斗地主在解决上特别具有挑战性,例如,巨大的状态/行动空间以及对竞争和合作的推理。为了应对这些挑战,我们用深度神经网络、行动编码和平行actor来加强经典的蒙特卡洛方法。这导致了一个纯粹的RL解决方案,即DouZero,它在概念上很简单,但却有效和高效。广泛的评估表明,DouZero是迄今为止最强大的斗地主人工智能程序。我们希望简单的蒙特卡洛方法能够在这样一个困难的领域中导致强大的策略,这一见解将激励未来的研究。
对于未来的工作,我们将探索以下方向。首先,我们计划尝试其他神经架构,如卷积神经网络和ResNet(He等人,2016)。第二,我们将在强化学习的循环中涉及竞标。第三,我们将像(Brown等人,2020)那样,在训练和/或测试时间将DouZero与搜索相结合,并研究如何平衡RL和搜索。第四,我们将探索off-policy学习以提高训练效率。具体来说,我们将研究是否以及如何通过经验回放来提高实际时间和采样效率(Lin, 1992 Zhang Sutton, 2017 Zha等人, 2019b Fedus等人, 2020)。第五,我们将尝试明确地对农民的合作进行建模(Panait Luke, 2005; Foerster et al., 2016; Raileanu et al., 2018; Lai et al., 2020)。第六,我们计划尝试可扩展的框架,如SEED RL(Espeholt等人,2019)。最后但同样重要的是,我们将测试蒙特卡洛方法在其他任务上的适用性。
原文标题:斗地主强化学习

|



 在森林里生活是一种
在森林里生活是一种